


미드저니는 인공지능 연구소이자 해당 연구소에서 개발한 인공지능 소프트웨어 입니다.
영어로 텍스트를 입력하거나 이미지 파일을 삽입하면 인공지능이 알아서 그림을 생성해 줍니다.

showcase 페이지를 보면 유저들에 의해 생성된 이미지가 많습니다.
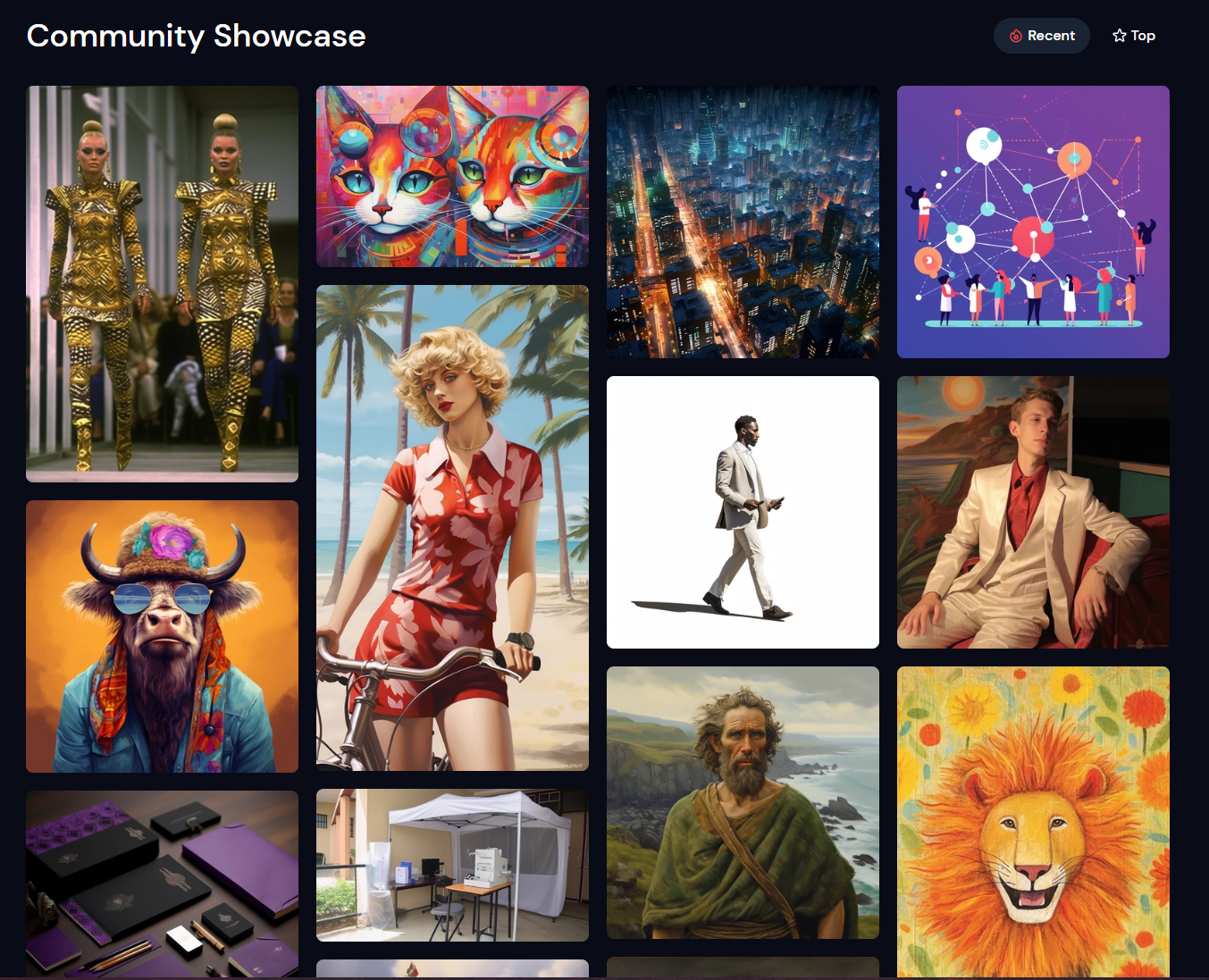
디스코드로 가 보면 더 많은 이미지가 생성되고 공유 되고 있습니다.
https://www.midjourney.com/showcase/recents/
www.midjourney.com
https://www.midjourney.com/showcase/top/
www.midjourney.com
1.크롬 > 개발자 도구를 이용해 이미지 저장 위치를 찾습니다.
다음과 같이 스크립트 구문으로 삽입 되어 있습니다.

2.파싱을 위해 이미지의 경로를 xpath 로를 가져오겠습니다.
script id="__NEXT_DATA__" 여기가 파싱을 위한 시작 점인 것 같습니다.
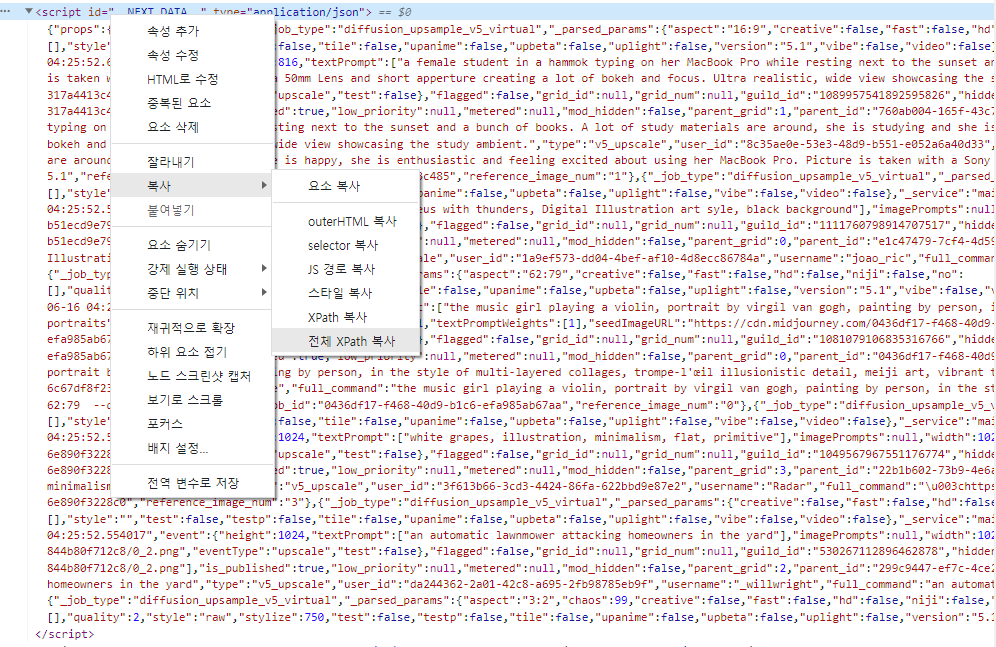
5.xpath 를 통해 가져온 경로를 통해 파싱 방법을 확인 합니다.
xpath를 통해 가져온 경로는 /html/body/script[1]/text() 이고, 이후 json 로 구성된 키 값을 파싱 하면 됩니다.
{"props":{"pageProps":{"jobs":[{"_job_type":"diffusion_upsample_v5_virtual","_parsed_params":{"creative":false,"fast":false,"hd":false,"niji":false,"no":["frame, frames, signature, text, watermark"],"quality":5,"style":"","test":false,"testp":false,"tile":false,"upanime":false,"upbeta":false,"uplight":false,"vibe":false,"video":false},"_service":"main","avatar_job_id":null,"avatar_job_index":0,"cover_job_id":null,"cover_job_index":0,"current_status":"completed","enqueue_time":"2023-06-15 09:37:30.248136","event":{"height":1024,"textPrompt":["Watercolor","christmas Clipart, painted christmas clipart, angel, children, tree, candle, candy cane, mistletoe, gift, baubles, carol singers, elves, toy sack, stocking, reindeer, poinsettia, holly, bows, hot chocolate, cookies and milk, chimney, sleigh, star, fireplace, snowman, gingerbread, Santa, Mrs. Claus, lights, lump of coal with bow, lump of coal, christmas illustration, white background","frame, frames, signature, text,
6.이미지 URL 파싱 코드를 완성 하였습니다.
이후 과정은 각자 완성해서 수행 합니다.
show_case_urllist = []
headers = {
f'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36',
}
response = requests.get(url, headers=headers, allow_redirects=True)
soup = BeautifulSoup(response.content, 'html.parser')
scripts = soup.find_all("script")
if len(scripts) > 0:
last_script = str(scripts[-1].string)
data = json.loads(last_script)
jobs = data.get("props").get("pageProps").get("jobs")
for job in jobs:
event = job.get("event")
if event:
seedImageURL = event.get("seedImageURL")
if seedImageURL:
show_case_urllist.append(seedImageURL)끝
'개발' 카테고리의 다른 글
| [slack-sdk] 특정 채널에 업로드된 업로드 파일 목록 가져오기 (0) | 2023.09.13 |
|---|---|
| [slack-sdk] 특정 채널의 전체 사용자 목록 가져오기 (0) | 2023.09.12 |
| [slack-sdk] 워크스페이스에 참여한 전체 사용자 목록 가져오기 (1) | 2023.09.11 |
| 봇 응답 제한(봇이 동작 하는 채팅방 제한) 하기 (0) | 2023.06.23 |
| [정보보안] 취약한 패스워드 해시 알고리즘을 사용 계정 찾기 (0) | 2023.06.13 |